Hydra is multistore database designed for transactional and analytical processing (OLTP, OLAP). It integrates online transactions with a scalable data lakehouse architecture. Hydra’s multistore eliminates the friction of moving and transforming data between a rowstore and columnstore with ETL processing. The transactional rowstore and analytical columnstore are managed within Hydra automatically, making it easier to build applications and analytics on realtime data.Documentation Index
Fetch the complete documentation index at: https://docs.hydra.so/llms.txt
Use this file to discover all available pages before exploring further.
.png?fit=max&auto=format&n=qsYyo-rksckbkjwh&q=85&s=01cba517e98a4f24c0358116bbf96532)
What’s a rowstore?
In a rowstore, table rows are stored sequentially. This arrangement enables fast retrieval of rows because the column values for each row are grouped together. A rowstore make it easy to add / modify a record, but may scan unnecessary data during read operations. For example, PostgreSQL is a rowstore..png?fit=max&auto=format&n=yL_jvOZ3zOfO9lO9&q=85&s=1baa33544d9cc4e9b187fcbffddbf4f8)
What’s a columnstore?
In a columnstore, tables are organized by storing all the values of each column in sequence. This format enhances the efficiency of filtering or aggregating columns but complicates the retrieval of individual rows due to the gaps between row data. For example, DuckDB is a columnstore..png?fit=max&auto=format&n=qsYyo-rksckbkjwh&q=85&s=cfcf75e1802b684b35bd678d7d9d642a)
What’s a data lakehouse?
A data lakehouse is a relational, column-oriented SQL database management system (DBMS) which decouples data storage from compute to unlock efficient analytical processing, scalability, and cost optimization. A lakehouse architecture allows data storage and data processing resources to be managed independently — storage can be scaled up to accommodate large datasets without needing to increase compute resources. Likewise, a lakehouse’s compute resources can be scaled up temporarily without affecting storage costs. A data lakehouse can achieve sub-second response times on complex analytical queries with:- Small to large datasets — billions of rows
- Filtering, complex JOINs, GROUP BYs, aggregate queries, window functions, CTE (Common Table Expressions), UNIONs, INTERSECTs, full text search, and more.
- timeseries, logging, events, traces data
What’s a multistore database?
Hydra is a multistore, “multi-workload data store” with the following core capabilities:- high throughput, ACID-compliant online transactional processing (OLTP)
- vectorized, parallel execution of online analytical processing (OLAP)
Hydra multistore, in depth
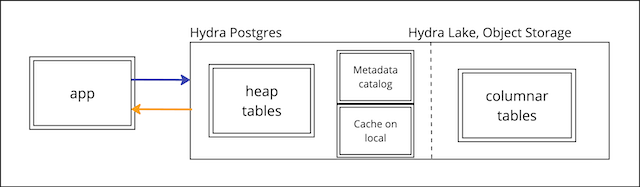
Hydra runs pg_duckdb, an open source program co-developed with the creators of DuckDB & MotherDuck which processes analytical queries 100-1000X faster than standard Postgres. pg_duckdb embeds DuckDB’s state-of-the-art analytics engine and features into Postgres. Also, pg_duckdb connects your Postgres database to Hydra’s bottomless, globally distributed object storage to unlock petabyte scale without a database migration. Voila, your lakehouse is ready. Here are the high-level principles:- Transactions write normally to Postgres tables (heap)
- DuckDB performs all SELECTs inside Postgres on row (heap) and columnar tables
- Columnar tables from Hydra Lake are cached to Postgres.
- DuckDB performs JOINs between row tables, columnar tables, and with each other.