Documentation Index
Fetch the complete documentation index at: https://docs.hydra.so/llms.txt
Use this file to discover all available pages before exploring further.
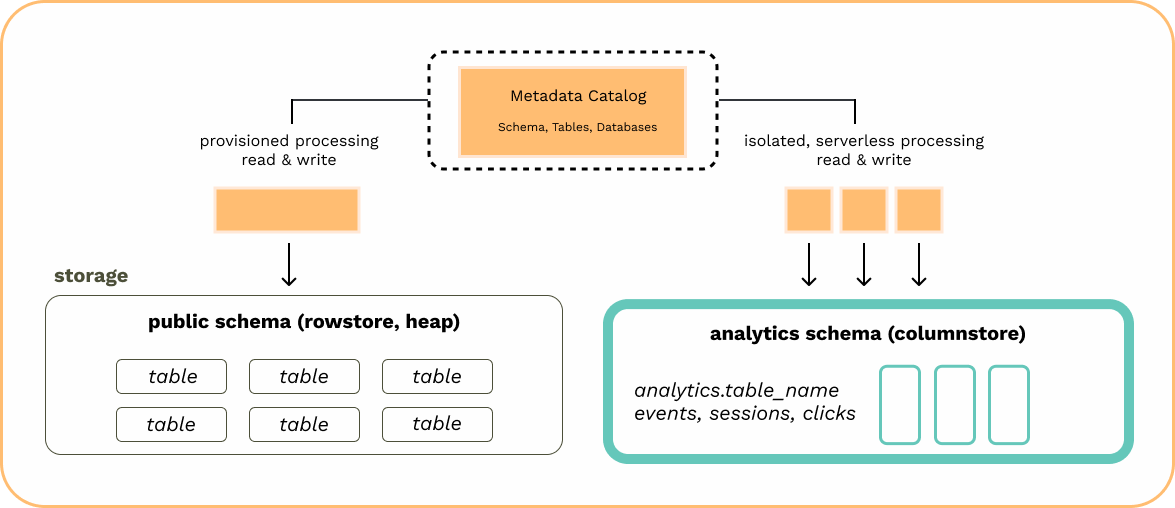
Using analytics (columnstore)
Hydra use its columnstore as the default table type. To create an analytics table, simply create a table normally. example:Creating rowstore tables with columnstore as default
To create a standard Postgres rowstore “heap” table you must include theUSING heap keyword.
JOIN rowstore and columnstore tables
To join a standard PostgreSQL rowstore “heap” table with an analytics columnstore table, use a standard JOIN operation. The database handles the differences between row-based and columnar storage internally during table creation, allowing joins to be performed as usual. example: consider high volume events and audit logs in the columnstore and user data in the rowstore tables.Switching the default table type to the Postgres rowstore
When CREATE TABLE is run a Postgres columnstore table, known as an “analytics” table is created. To switch the default DDL from Postgres analytics columnstore to the rowstore, change thedefault_table_access_method to heap.
ALTER USER, that user must also be a superuser to use rowstore tables. Superuser can be granted to any user:
Creating columnstore tables when rowstore is default
When the default is switched toheap, CREATE TABLE will create a heap table without needing to add USING heap. With the default changed, to create a Postgres columnstore table you must include the USING duckdb keyword.
Analytics limitations (columnstore)
Note that all limitations listed below are for analytics tables only. For example, indexes are supported on Postgres’ standard tables (rowstore), but not supported for query acceleration on analytics tables (columnstore). This is generally not a concern as analytics tables are already highly optimized for analytical workloads and provides excellent query performance through optimized data storage and processing.Limitations
Limitations
- GRANT. By default, superuser is required to access analytics tables. This can be modified to use a different role by support request.
- ALTER TABLE statements
- Instead, use
SELECT duckdb.raw_query($$ ALTER TABLE ... ; $$)to execute directly with DuckDB.- Cannot add generated columns after table creation with the above command.
- Instead, use
- JSONB
- Instead, use
json
- Instead, use
- ENUM, SERIAL, TSVECTOR data types
- Some types cannot be used when joined with analytics tables.
- ENUM (PR #193), domain types (PR #532)
- Custom functions or extensions
- Instead, use triggers to execute in Postgres before being passed to
duckdb.
- Instead, use triggers to execute in Postgres before being passed to
#>and#>>JSON operators are not supported when running a query that uses analytics tables.- While materialized views can be specified
using duckdb, these views cannot be refreshed. - Indexes are not supported on analytics tables, including primary, unique, and foreign keys.
- Features that rely on foreign keys, like
REFERENCES,ON DELETE CASCADE - Partitioned tables are not supported on analytics tables.
- Instead use analytics tables for specific table partitions underneath the master partitioned table. For additional guidance, please feel free to contact support@hydra.so
- Prepared statements
- SAVEPOINT and subtransactions